LatticeのSERDES搭載FPGA、6Gbps対応の新ファミリが登場
Lattice Semiconductor(ラティスセミコンダクター)は2011年11月29日、高速シリアルインタフェース用SERDES(シリアライザ/デシリアライザ)を集積した中規模FPGAの新ファミリ「LatticeECP4」を発表した。低消費電力・低コストを特徴とするSRAMベースのFPGAで、同社既存の「LatticeECP3」に比べて、SERDESの最大動作速度を3.2Gビット/秒から6Gビット/秒と約2倍に高めた(図1)。「データ伝送速度が最大6Gビット/秒まで通信規格に対応できるSERDESを低コストのFPGAでも利用したいという、通信機器市場の要求に応えた製品だ」(同社Business Group Director of Marketing, Silicon/SolutionsのShakeel Peera氏)(図2)。2012年上半期にエンジニアリングサンプル品の出荷を始め、同年下半期には量産品の出荷を開始する予定である。
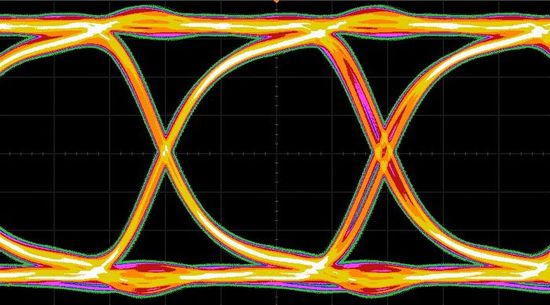 図1 6Gビット/秒のデータ伝送波形である。出典:Lattice Semiconductor
図1 6Gビット/秒のデータ伝送波形である。出典:Lattice Semiconductor
新ファミリのLatticeECP4では、集積規模の異なる6品種を用意した。例えば、最大規模品「ECP4-250」は、6Gビット/秒のSERDESを16チャネル搭載する。チャネル当たりの消費電力は175mW未満だという。さらに、PCI Express 2.1やSerial RapidIO 2.1、10Gビット/秒対応イーサネットMACなどをハードマクロ形式のIPコアとして集積した。これらの回路をユーザーがプログラマブルロジック領域にソフトマクロとして実装する場合に比べて、「所要のロジック容量をルックアップテーブル(LUT)換算で10万個も削減できる」(同氏)という。
ロジックやメモリの容量も拡大

LatticeECP4ではこの他、既存ファミリに比べてプログラマブルロジックと内蔵メモリの容量をそれぞれ拡大した上、デジタル信号処理性能や汎用入出力の動作速度も向上させた。
例えば、最大規模品では、プログラマブルロジックの容量がLUT換算で24万1000個、ブロックメモリの容量が10.62Mビットである(図3)。それぞれ既存ファミリに比べて66%、42%増加した。
デジタル信号処理性能については、積和演算の実行性能を既存ファミリの7倍相当まで高めたという。18×18乗算器をベースにしたDSPブロックの集積数を従来の1.75倍に相当する576個に増やすとともに、新たにプリアダー(前置加算器)とダブルデータレート(DDR)動作の「ブースターロジック」を用意することで、DSPブロック当たりの実効的な性能を4倍に向上させることで達成した。「4×4のアンテナ構成をとる40MHz帯域のMIMO(Multiple Input Multiple Output)システムを低コスト/低消費電力で実現できる」(同氏)と主張する。
汎用入出力については、CDR(Clock Data Recovery)機能を備え、1.25Gビット/秒で動作する端子を40本用意した。既存ファミリもCDR付き端子を搭載していたが、動作速度は800Mビット/秒にとどまっていた。新ファミリを使えば、「高速シリアルインタフェース用SERDESを使わなくても、ギガビットイーサネットポートを実装できる」(同氏)という。
製造技術は変えず

LatticeECP4も、既存ファミリと同様に、65nm世代の半導体プロセス技術で製造する。最大手FPGAベンダーが最新製品に適用している28nm世代のプロセスとは数世代の隔たりがある。
これについて同社は、次のように説明する。「費用対効果で見ると、まだまだ65nm世代の方が優れている。例えば、ウエハーコストは28nm世代の半分程度で済む。しかも当社は、プログラマブル領域に低コスト化と低消費電力化に向けて最適化した独自のアーキテクチャを採用している。さらに、6Gビット/秒のSERDESを集積しながらも、パッケージに高コストのフリップチップ品ではなく、低コストのワイヤーボンディング品を使える工夫も施した。これらの結果、LatticeECP4では65nm世代を引き続き用いながらも、28nm世代の他社品よりもコストと消費電力を低く抑えられる」(同氏)(図4)。
なお同社は2011年5月に、LatticeECP4の次世代品となる「LatticeECP5」で、プロセス技術を現行の65nm世代から、一気に28nm世代に微細化する表明している(参考記事 )。45nm世代や32nm世代はスキップする計画だ。
(薩川 格広)
Copyright © ITmedia, Inc. All Rights Reserved.
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。