SystemC仮想プラットフォーム性能の事前評価の決め手に
USB2.0のソフトウエアスタックの性能を事前に評価してみた。
SoC(system-on-chip)設計の初期段階からソフトウエアの性能を評価し、最適化するにはどうすべきか。SoC 設計に組み込まれるソフトウエアがかつてないほどに増えたため、プログラマやシステムアーキテクトはこのような難しい問題に直面している。この問題を解決するため、プログラマは仮想プラットフォームに注目している。このプラットフォームでは、ソフトウエアを使い、目的とするハードウエアのアーキテクチャと機能をモデル化する。
他の支援ソフトウエアを使ってこの作業を慎重に行えば、こうしたプラットフォームが効果的であることがわかるだろう。組み込みソフトウエアの機能と、最終ハードウエアとの関連をどう調整するかという重要な性能指数を早い段階で評価できるからだ。仮想プラットフォームでは、CPU効率、データ転送レート、キャッシュミスレート、割り込み遅延、機能のホットスポットなどの性能を予測できる。
仮想プラットフォームの特性とメリットを理解するため、USBシステムのソフトウエアスタックの性能を評価する場合を考えてみよう。開発者の狙いが的中し、転送レート480Mビット/秒のUSB 2.0はリアルタイムのオーディオ/ビデオデータの伝送に広く利用されるようになった。そして、今やUSBはセットトップボックスや携帯電話機などのマルチメディア製品分野にもその範囲を広げつつある。
USBでのやりとりには複雑なプロトコルが必要なことに加え、ハードウエアとソフトウエアが互いに深く関係するため、こうしたプラットフォームが特に役立つ。USBが本当に正しい選択かどうかを判断するには、ソフトウエアアーキテクトができるだけ早いうちに、USBシステムのソフトウエアを検証するだけでなく、そのソフトウエアがCPUにかける負荷と割り込み遅延の影響を予測しなくてはならない。
このような性能を予測するには、プロセッサ、キャッシュ、システムメモリー、USBペリフェラル、USB EHCI(extended host-controller interface)、USBデバイスを含む、実ハードウエアの機能を厳密にモデリングするための仮想プラットフォームが必要となる。また、ソフトウエアスタック内の機能ホットスポットを探し、機能の実行にかかる時間を正確に予測するにはプロファイリングツールが必要となる。仮想プラットフォームで得られた結果が理論上の予測と一致していれば、実ハードウエア上のUSBスタックの性能を評価できるだけの十分な安定性がプラットフォームにあることが証明される。また、開発者がソフトウエアスタックを修正した場合には、プラットフォームは性能の変化を正確に反映する。
今回の例では、セットトップボックス用チップに集積されているDVR(digital-video-recorder)回路内で動作する、USBシステムのソフトウエアスタックの性能評価方法を考えた。DVRには、ビデオ/オーディオデータストリームを記録・再生するためのUSBのHDD(ハードディスクドライブ)が内蔵されている。USBソフトウエアスタックは、サンプルのシングルスレッドDVRアプリケーションを含み、このアプリケーションがドライブに対する読み出し/書き込み処理を実行する。
仮想プラットフォームがDVRハードウエアの動作を詳細に模倣すると、重要なタイミングパラメータが明らかになる。具体的には、プラットフォームによってUSBホストコントローラとHDD、システムメモリー、キャッシュメモリーをモデル化する。このプラットフォームの利点は、SystemCで記述されたトランザクションレベルのモデルを含むことである。このことから、複雑な組み込みソフトウエアを評価するために仮想プラットフォームを構築する方法が有効であることがわかる。一般に開発者がシステムのハードウエア部品をモデル化するときは、トランザクションレベルのモデルよりも抽象度が低いRTL(register-transfer-level)モデルを使う。
プラットフォームの設定
この仮想プラットフォームは、USB 2.0 EHCI、USBのHDD、キャッシュシミュレータ、ホストプロセッサ命令セットシミュレータ、システムメモリーで構成されている。USB 2.0 EHCIはホストコントローラの機能を模倣して、480Mビット/秒のデータレートに関連する正確なタイミング値を得る。加えて、メモリーモデルに基づいたメモリーアクセス時間とEHCIレジスタの読み出し/書き込み時間を通知する。また、このEHCIは、システムメモリーへの非キャッシュアクセスを実行できるDMAマスターとしても機能する。
命令アクセスとデータアクセスのすべてを追跡するため、USBソフトウエアスタックは命令セットシミュレータ上で動作する。開発者はトランザクションレベルのハードウエアモデルからこのシミュレータを作成する。この命令とデータの追跡が仮想プラットフォームに渡され、CPU利用率、キャッシュミスレート、割り込み遅延を評価する。また、柔軟性と拡張性に優れたモジュラープロファイリングツール「Flexperf」によって機能のホットスポットを特定できるため、ソフトウエアスタックのデバッグを容易に行える。
このシステムでは、HDDをセクターごとに分割してI/Oファイルとしてアクセスする。システムはUSB Implementers Forumが策定した「bulk-only」仕様を含む大容量記憶装置仕様に準拠する。その結果、エンドポイント0からアクセス可能な標準デバイス要求のすべてを実行する。また、エンドポイント1と2から、DVRに関連する一部のSCSIコマンドも実行する。
設定可能なキャッシュメモリーをモデル化するキャッシュシミュレータは、オープンソースのトレース駆動型キャッシュシミュレータDinero周辺のラッパーを含んでいる。システムプロセッサについては、命令セットシミュレータ周辺のラッパーが動作周波数216MHzのSTMicroelectronics社 C2 CPUコアをモデル化する。このシミュレータがプロセッサのメモリーアクセスをトランザクションレベルのモデルに変換する。開発者はシステムメモリーをRAM配列としてモデル化した。概ね英ARM社のAHB(advanced high-performance bus)に基づいたチャンネルと、開発者がUSB上に大まかにモデリングしたチャンネルを介してモデルはすべて接続される。
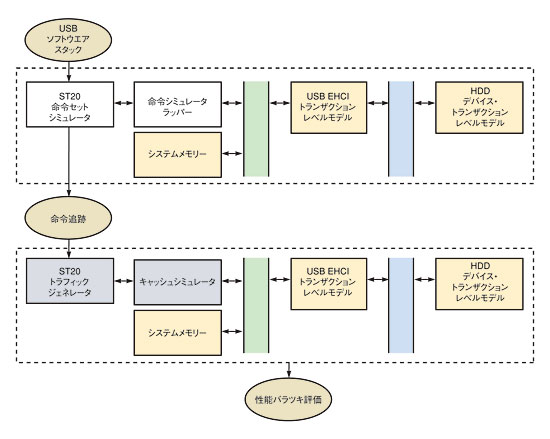 図1 2ステッププロセス最初のステップでは、ホストプロセッサをモデル化する命令セットシミュレータ上で、USBソフトウエアスタックを実行する。このようにしてすべての命令およびデータメモリーへのアクセスとハードウエア割り込みを記録する追跡ファイルを生成する。次のステップでは、トラフィックジェネレータにこの追跡ファイルが渡される。トラフィックジェネレータがプラットフォームのトランザクションレベルのモデルにデータを供給する。
図1 2ステッププロセス最初のステップでは、ホストプロセッサをモデル化する命令セットシミュレータ上で、USBソフトウエアスタックを実行する。このようにしてすべての命令およびデータメモリーへのアクセスとハードウエア割り込みを記録する追跡ファイルを生成する。次のステップでは、トラフィックジェネレータにこの追跡ファイルが渡される。トラフィックジェネレータがプラットフォームのトランザクションレベルのモデルにデータを供給する。ソフトウエアの性能を評価するためにプラットフォームを起動するには2つのステップが必要となる(図1)。最初のステップでは、USBソフトウエアスタックをST20命令セットシミュレータ上で走らせる。この作業により、命令メモリーとデータメモリーへのすべてのアクセスに加え、ハードウエアによるすべての割り込みが記録された追跡ファイルが生成される。次のステップでは、トラフィックジェネレータが追跡ファイルを解析し、トランザクションの正確なチャンネル上に、等価なトランザクションレベルの命令を生成する。
この2ステップの評価プロセスは、チップ設計の通常のプロセスを表している。設計者は最初のステップで、設計を機能ブロックに分ける。各機能ブロックは目的のアプリケーション機能を実現するため並列動作する。したがって、最初のプラットフォームには機能モデルしかなく、基準時間は考慮されていない。設計者は同じ機能ブロックを使って、タイミングモデルや性能モデルなどいろいろとモデル化する。これがステップ2である。この手法により、ユーザーは一般的な機能群を使用してマイクロアーキテクチャを実行できるようになる。
その結果、外部に依存しない共通のSystemCベースのプラットフォームが構築できる。このSystemCシミュレータ時間が性能評価の一つの基準になる。同様に、このシステムではSystemCで記述されたトランザクションレベルのモデルとして命令メモリーとデータメモリーを抽象化し、アクセス時間を厳密にシミュレーションする。この2ステップアプローチにより、キャッシュシミュレータをトラフィックジェネレータにリンクすることが容易になる。これは、ハードウエア上のキャッシュの影響をモデル化する一つの方法となる。
性能パラメータ
仮想プラットフォームによって生成される性能の値は、次の前提に基づいている。すなわちSystemCシミュレータがアプリケーションを実行するのにかかる時間が、そのアプリケーションを実ハードウエアで実行するのにかかる時間に相当するということだ。しかし、アプリケーションの実行時間は、命令アクセス時間と、EHCI、キャッシュメモリー、その他の機能に関連する遅延によって異なってくる。これらの値から、CPU利用率、データ転送レート、キャッシュミスレート、割り込み回数などの重要な性能パラメータを決定できる。
これらのうち、CPU利用率―CPUがソフトウエアスタックの実行に費やす時間の割合―は、スタックの性能を評価する上で最も重要なパラメータである。CPU利用率は、CPUが他のアプリケーションを実行できない時間を表す。しかしCPU利用率を評価するには、最初にCPUのアイドル時間を測定し、これを差し引く必要がある。アイドル時間は、アイドルスレッド内にソフトウエアスタックが費やす時間である。この間、ハードウエアによって割り込みが生成されるのを待つ。つまり、サンプルのDVRアプリケーションがHDDにある1ブロックのデータのやりとりをコミットしてから、次の転送を開始するハードウエア割り込みが発生するまでの時間をいう。厳密に言うと、この間、USBソフトウエアスタックがCPUを占有していないため、合計時間からこの時間を差し引く必要がある。
ここでFlexperfプロファイリングツールを起動し、CPUがアイドルスレッド内で費やす時間を測定する。このツール、すなわち入力追跡ファイルにはプログラムカウンタとそれに相当する時間、マップファイルを含む。このマップファイルは、アイドルスレッドに関連付けられる開始アドレスと終了アドレスを定義している。これらの入力からプロファイリングツールが計算したアイドル時間をCPU時間から差し引いて、CPU利用率の正確な値を求める。USBのデータ転送レートは、USBを介して移動する総データ量、すなわち制御やバルク情報、プロトコル情報などを、サンプルアプリケーションの実行に要した総シミュレーション時間で割って求める。しかし、USB 2.0の480 Mビット/秒は理論上の最高レートにすぎない。実際のレートはこれよりもはるかに低い。プロトコルのオーバーヘッド時間や、特にEHCIキャッシュが小さい場合にシステムメモリーからスケジュールとデータをフェッチする時間がかかるためだ。ソフトウエアがデータをハードウエアに送る速度もデータ転送レートに影響を及ぼす。
Dineroオープンソースのキャッシュシミュレータにメモリートラフィック情報を与えると、命令ミスやデータミスレートなど総合ミスレートに関する統計が生成される。このデータから最適なキャッシュ構成を決めることができる。ST20ホストプロセッサの追跡ファイル内に割り込み数を記録するには、ST20ラッパーが捕まえた割り込み数をカウントする。これらの基本的な性能指数から、他のパラメータを導くことができる。つまり、命令セットシミュレータが報告する実行済み命令数の合計、CPUの実行時間(合計時間−アイドル時間)、CPUの総命令実行時間、総CPU読み出し/書き込み時間などがわかる。
このケースで仮想プラットフォームから得られる性能結果は、数学的に導き出せるものではあるが、この記事の範囲を超えてしまう。しかし、これらの数値の要素として、最大SCSIバッファサイズ、読み出し/書き込み動作時のデータ転送量との関係や、システムソフトウエアによる割り込み処理時間、HDDに対するSCSIコマンドの処理時間、といった数字が得られる。
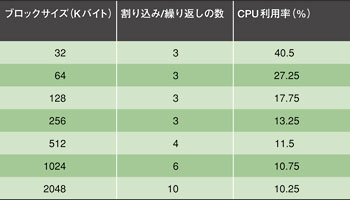 表1 CPU利用率に対するブロックサイズの影響
表1 CPU利用率に対するブロックサイズの影響 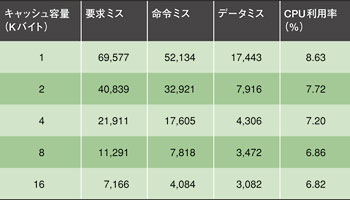 表2 CPU利用率に対するキャッシュパラメータの影響
表2 CPU利用率に対するキャッシュパラメータの影響 仮想プラットフォームを使えば、ブロックサイズや、総データ転送量、キャッシュパラメータ、データ転送メカニズム、スタックサイズ、CPU利用率など重要な性能データが得られる。ハードウエアを使ったときの結果が、仮想プラットフォームの予測と一致していれば、その開発を正当化できる。例えば、仮想プラットフォームでは、ブロックサイズ、すなわち各読み出し/書き込み処理時のデータ転送量が増えるにつれ、CPU利用率が下がっていることがわかる(表1)。しかしその減少分は、ブロックが大きくなるほど少なくなっている。さらにこのプラットフォームでは、転送されたデータ量が増えるにつれてCPU利用率が低下することを予測している。これらの予測は次のような仮定を前提としている。すなわち、ST20-C2コアの動作周波数が216MHz、キャッシュヒット遅延が10ns、1ワードのメモリーアクセス時間が160ns、ハードウエア割り込み待機前の最大バッファリング可能データ量が256Kバイトとしている。キャッシュモデルは、8Kバイトの2ウェイセットアソシアティブ命令/データキャッシュで、それぞれに16バイトのブロックが割り当てられていると仮定している。USB転送レートは80Mバイト/秒としている。
驚くことに、このプラットフォームはキャッシュサイズがUSBスタックの性能にほとんど影響しないことを示している。実験1回ごとに、キャッシュの主なパラメータであるサイズ、アソシエティビティ、ブロックサイズを変えてみた。しかし、パラメータが違えばアプリケーション全体の要求ミスに大きな差は出るが、CPU利用率への影響は微々たるものだ。このシミュレーションの段階では、アプリケーションの実行に要する総CPU時間を、デバイスの列挙を含めた初期化にかかるCPU時間から差し引くことでCPU利用率を求めている。その結果、HDDに対する読み出し/書き込み処理で、命令メモリーとデータメモリーの両方にほぼ規則的なアクセスが発生していることが明らかとなった。すなわち、空間的にも時間的にも部分的な処理にすぎないこの読み出し/書き込み処理では、HDDに対する総ミス数が、キャッシュパラメータの変化に関係なくほぼ一定になるということだ。
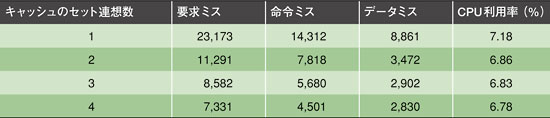 表3 CPU利用率に対するキャッシュメモリーの影響
表3 CPU利用率に対するキャッシュメモリーの影響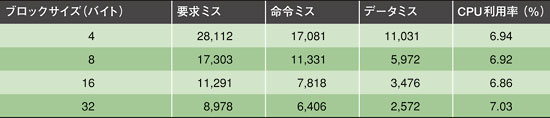 表4 CPU利用率に対するブロックサイズの影響
表4 CPU利用率に対するブロックサイズの影響表2は、キャッシュサイズを変えた結果をまとめたものである。命令キャッシュとデータキャッシュは常に同じで、アソシエティビティは2ウエイ、ブロックサイズは16バイトである。表3は、16バイトブロックで構成される8Kバイトのキャッシュのアソシエティビティを変えた場合の結果を示している。表4は、2ウエイアソシエティビティの8Kバイトキャッシュのブロックサイズを変えたときの結果である。ここでは、キャッシュヒット遅延が5ns、4ワードアクセスにかかる時間が160ns/ワードと仮定されている。
キャッシュサイズがCPU効率に及ぼす影響が小さいことと対照的に、EHCIがメモリーとの間でデータをやりとりする方法には大きな違いがある。このcopy-semantics(コピーする意味のある)アプローチでは、キャッシュされた領域から、EHCIがアクセス可能なキャッシュされない領域にデータを移動する。Noncopy semantics(コピーする意味のない)アプローチでは、目的のデータを含むメモリー領域をEHCIがアクセスすると仮定している。このアプローチでは、そのメモリー領域はキャッシュされず、その領域へのダイレクトポインタがEHCIに渡される。
この2つの方法で性能指数が大きく異なる理由は、noncopy semanticsでは1つのメモリー領域から別の領域へのデータコピーが発生せず、すべての移動命令が無効となるため、大量のデータを移動するときの負荷を大幅に削減できるからだ。例えば、1回につき256Kバイトのデータ転送を64回繰り返し、全部で32Mバイトのデータを転送するとき、仮想プラットフォームで示されるデータレートとCPU利用率はそれぞれ、copy semanticsアプローチで5051Kバイト/秒と6%、noncopy semanticsアプローチで7700Kバイト/秒と40%となる。
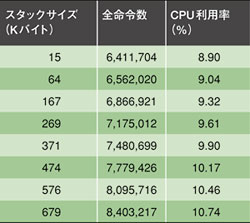 表5 CPU利用率に対するスタックサイズの影響
表5 CPU利用率に対するスタックサイズの影響 スタックサイズを仮想プラットフォームで評価すると、スタックが小さいほどCPU利用率が下がることがわかり、直感に反する結果を見せている(表5)。CPU利用率とともにスタックが大きくなるほど、アプリケーションの実行命令数が増えることを表5は示している。
しかし、ヒープサイズを変更しても、結果は変わらない。ヒープとは、ソフトウエアアプリケーションが割り当てと割り当て解除を直接行うメモリーの領域のことである。一方、コンパイラはアプリケーションではなくスタックを管理する。他のケースと同様、この結果はプロセッサの動作周波数216MHzとデータレート10Mバイト/秒の条件で得られているのにもかかわらず、このような驚くべき結果が得られるのは、スタックがコンパイラによって制御されるためであり、サイズが関係しないからである。
仮想プラットフォームで良好な結果が得られるといっても、ハードウエアの動作と矛盾するところは依然としてある。1つは、ST20プロセッサトラフィックジェネレータのモデルがシンプルすぎることだ。各命令の実行ステージの平均時間が一定だと仮定されているが、実際はそうともかぎらない。また、トラフィックジェネレータではプロセッサパイプラインもパイプラインの停止もモデル化されていない。しかし、これらの要因の中には互いに相殺できるものもあるため、かなり正確な結果を出せる。
現在は、より複雑なプラットフォームの構築と、ソフトウエアスタックの性能を評価するためのシームレスな方法を考案することに注力している。たとえば、仮想プラットフォームをFlexperfなどのプロファイリングツールと組み合わせることで、プログラマとシステムアーキテクトが組み込みコードの性能を統一された方法で評価し、性能向上できるような取り組みを進めている。
Copyright © ITmedia, Inc. All Rights Reserved.
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。