ビデオアーキテクチャの正しい選択:ここが差異化のポイント(2/3 ページ)
狙いを定めて撃つ
規模も安定性もある市場に対しては、SoC設計を提供するということも道理にかなっている。携帯機器向け地上デジタル放送規格(ワンセグ)が採用されつつある一部のアジア市場もその例だ。ルネサス テクノロジが最近発表した「SH-Mobile L3V」は、DVB対応の携帯機器向けプロセッサとして使用できる(図1)。ルネサスのビジネスディベロップメント部門ディレクタを務めるBrian Davis氏によれば、このチップはスーパースケーラ方式の「SH-4」アーキテクチャに基づくプロセッサコア「SH4AL-DSP」を搭載しているという。SH4AL-DSPには、ソフトウエアでオーディオコーデック処理を行うためのDSPサブシステムが追加されている。このSoCはわずか2つの特定地域向けモバイルテレビ用に開発されたものだとはいえ、その地域でも幅広いオーディオコーデックが使用されていることを考えれば、どうしてもソフトウエア的なアプローチが必要になる、とDavis氏はいう。SH4AL-DSPには、OS、プログラムコード、ソフトウエアオーディオコーデック用に十分なメモリー空間が確保されている。
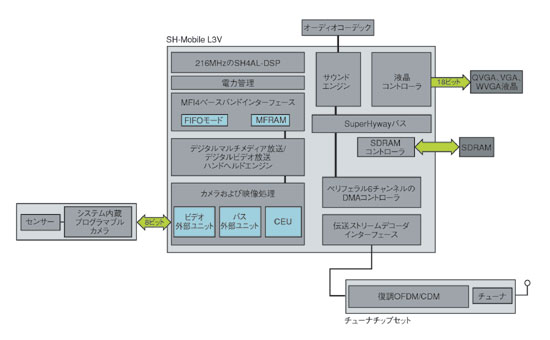 図1 ルネサスのSH-MobileL3Vの回路ブロック ルネサスは、SH4AL-DSPコアをハードワイヤードされた大規模なビデオプロセッサで囲い、モバイルビデオレシーバの価格/パフォーマンス目標を達成している。
図1 ルネサスのSH-MobileL3Vの回路ブロック ルネサスは、SH4AL-DSPコアをハードワイヤードされた大規模なビデオプロセッサで囲い、モバイルビデオレシーバの価格/パフォーマンス目標を達成している。一方でルネサスはビデオ信号処理に関しては、ハードウエアのみのアプローチで実現できると判断した。MPEG-4とH.264のビデオプロファイルをサポートするだけでよいからだ。また、ビデオデコーダと静止画像のコーデックの処理をソフトウエアで代替すれば、電池の使用時間は短くなると思われた。そのため、この設計ではビデオ、デジタルカメラの画像処理、CPUの周辺回路制御にハードウエアブロックを集中させ、独自開発した「Super Hyway」と呼ぶ内部バスでそれらのブロックを接続している。「ビデオデコーダが実装されているハードウエアは、関数を組み込んだステートマシン群のようなものである。MPEG-4とH.264には、これらのステートマシンの一部を共有できるような機能がいくつもある。当社の研究では、ソフトウエアを追加すれば同じハードウエアブロックを使って動画像圧縮方式『VC-1』に対応できることが分かっている」とDavis氏は説明する。
ハードウエアを中心とした設計は、ソフトウエア処理を行う場合に比べ電力効率を大幅に向上させることができる。ただ、電力消費量に影響を及ぼす要因が多すぎるため、消費電力値の比較は非常に難しい。例えば、ある特定の消費電力値に、ビデオスケーリングと色空間の変換に要する電力や、ディスプレイドライバで消費する電力が含まれているのかどうかを確認する必要がある。Davis氏によれば、同社のSoCはオーディオ/ビデオデコードとディスプレイの前処理をCIF(common intermediate format:352×288画素)の解像度であれば約200mWで実行できるという。
ルネサスはこのアーキテクチャを2段階で顧客に提供している。日本市場では、NTTドコモとの統合アプリケーション/ベースバンド設計の基盤となっており、完全なリファレンス設計として提供されている。韓国市場においてルネサスはシステムインテグレータと提携し、現地のニーズに合ったリファレンス設計にカスタマイズしている。
同じような事例はほかにもたくさんある。例えば米Qualcomm社は、ビデオゲーム機能を搭載した携帯電話機に自社の「CPU+ハードウエア」アーキテクチャで対応している。ルネサスが小さな市場ごとに1つのチップを提供しているのとは異なり、Qualcomm社はゲーム機能を搭載した携帯電話機市場に対して価格帯ごと、処理性能ごとのSoCを設計している。Qualcomm社のシニアプロダクトマネジャであるDave Ligon氏は「演算性能に差があれば、アーキテクチャ上のトレードオフも異なって然るべきだ。当社はこの市場を、コストが最重視されるマルチメディアホン、高機能携帯電話機、そしてゲーム要件が厳しいコンバージェンスプラットフォームの3つのセグメントに分けている」という。
Qualcomm社が提案するアーキテクチャには、これら3つのセグメントが反映されている。例えばマルチメディアホン向けには、ジオメトリ処理用にアプリケーションDSPコアを、ソフトウエアベースのラスタライゼーション用にARMコアをそれぞれ実装している。適切に配置されたローカルメモリーをうまく利用することで、このレベルでのチップパフォーマンス目標を実現可能とする。
高機能携帯電話機向けにはハードウエア化されたラスタライゼーション機能が搭載されている。Zバッファは可視ピクセルのみをパイプライン処理する。ジオメトリDSPコアはラスタライズエンジンに直接接続されているため、内部バスや共有メモリーで消費される電力分を節約できる。ラスタライズエンジンは、小型液晶パネル向けの信号を生成するほか、簡単な2次元処理を行うモバイルディスプレイコントローラを駆動する。
ハイエンド携帯電話機向けのコンバージェンスプラットフォームには、米ATI Technologies社のグラフィックチップ「IMAGEON 2300」の派生コアとモバイルディスプレイコントローラの拡張バージョンを搭載している。「コンバージェンスプラットフォームのグラフィック処理性能は、私が米Silicon Graphics社に勤務していたときにヒットしたワークステーション『Silicon Graphics Octane』の性能をやや上回っている。そして、これは携帯電話機に内蔵されたSIP(system in package)の1つだ」とLigon氏はいう。
これら3つのプラットフォームのハードウエア上の大きな違いは、グラフィックAPIによって隠蔽されて、実際にはほとんど分からない。そのため、ゲームソフトウエアの開発者にはこの3つが同じプラットフォームのように感じられるかもしれない。OEMメーカーは製品ラインで機能の違いを区別できるだろうが、ソフトウエアのインターフェースは基本的に何ら変わるところがない。このアプローチであればさまざまな演算処理の電力効率を最大限に高められる。しかし、これらQualcomm社の3種類のチップが示すように、柔軟性があるということは、そこからさらに別のチップ設計が必要になることを意味する。資金力があり、顧客との関係も確立されていて、大きな市場シェアを取る自信のある企業にとっては、そうしたトレードオフは有利に働く。しかし、すべての企業がそのような立場にあるわけではない。
プログラマビリティを加味する
CPUを中心としたプログラマブルコアをハードワイヤードのエンジンが取り巻いているアーキテクチャから、専用化されたエンジンそのものがプログラマブルで柔軟性の高いアーキテクチャへと進化するのは自然なことだ。米Texas Instruments社の「DaVinci」プラットフォームはその第一歩だといえる(図2)。「1つのチップ内でハードワイヤードブロックと、プログラマブルブロックの位置が分かれている」と、TI社のRay Simar氏はいう。さらに、「アーキテクチャの概念から設計をスタートするのではなく、まずアプリケーションの要件を理解し、それらが時間の経過とともにどのように変わっていくのかを知ることが重要である。アーキテクチャを考えるのはその後だ」と付け加える。
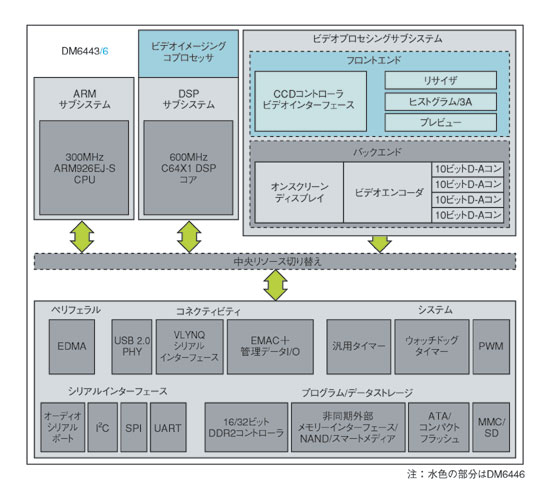 図2 TI社のプラットフォーム「DaVinci」 TI社のDaVinciアプローチでは、CPU、独立したDSPコア、そしてレジスタ構成が可能でプログラマブルなブロックを目的に合わせて組み合わせる。
図2 TI社のプラットフォーム「DaVinci」 TI社のDaVinciアプローチでは、CPU、独立したDSPコア、そしてレジスタ構成が可能でプログラマブルなブロックを目的に合わせて組み合わせる。機能ブロックをプログラマブルにするためのコストは徐々に下がってきている。「どの企業にとっても消費電力を抑えることはより難しい問題になりつつある。しかし、電力管理手法とメモリーアーキテクチャの両方に優れていれば、プログラマブルブロックをハードワイヤードブロックの電力消費量に近づけることが可能だ」とSimar氏は語る。
またSimar氏は、演算の粒度とブロックの機能モードの数により、ブロック内にプログラマブルな範囲が発生すると指摘する。例えば、動き検出や比較機能などの場合、その処理方法はレジスタにプログラムするステートマシンでアプリケーション要件のすべてを満たすことのできる固定データフローモデルに非常に近い。そのほかのケースでは、処理方法の異なるものが多すぎるか、機能がデータに大きく依存しているため、それに対応できるほどの柔軟性があるのはストアドプログラムとプログラムカウンタを使うチップだけである。TI社には、自社のDSPコアのほかにもさまざまなオプションがある。
徐々にプログラマビリティが要求されてきたものにDMAがある。多くの設計者が思いつく機能の1つである。マルチメディアサブシステム内のデータ移動は非常に複雑で、データに依存し、変化しやすい。単純にデータブロックとDRAMを接続しようとしても、大抵は失敗に終わる。TI社の製品はこの問題を解決するため、ブロックが実行する機能のすべてのワーキングセットを保持できるだけの容量を持つSRAMを内蔵している。必要に応じてフロースルーアーキテクチャ、そして機能ブロックとDDR DRAMの要件にDRAMトラフィックパターンを合わせるためのプログラマブルDMAコントローラを組み合わせている。
マルチプロセッシング
ユースケースに始まり、タスクを特定し、それらを構成可能なハードウエアブロックまたはソフトウエア駆動ブロックに分割するという同じ分析方法であっても、設計者によって異なる結論が導かれることがある。例えば、米NVIDIA社の「GoForce」にはハードワイヤードのエンジンが搭載されているが、処理の大半は拡張命令セットを組み込んだ米Tensilica社のプログラマブルDSPコアで実行される。DSPコア自体は小さな空間で同じパターンを繰り返しているにすぎないが、命令拡張機能が固定ハードウエアに実装されている。
「ハードウエアとして何を実装するのかはよく考える必要がある」と、NVIDIA社の製品マーケティング部門ディレクタであるGeoff Ballew氏はいう。固定ハードウエアならば電力効率を最大限に引き上げることができる。DSPブロック数を増やした場合よりもその効率は高く、従来のDSPコアに比べてもはるかに高い。しかし慎重に選択すべきである。例えば少し工夫すれば、さまざまなコーデックに共通する固定機能であるかのようにブロックを再利用できる場合もある。
問題の1つは、システムレベルで電力効率をプロファイルする優れたツールが存在しないことだ。電力消費量の多いブロックがどれかを特定することは難しい。そのブロックが特定できれば、NVIDIA社の製品でさらに分析して、ブロック内の回路を細粒度でオン/オフする動的クロックゲーティング手法によって電力消費量は最小限に抑えられる。
米Broadcom社のシニアエンジニアリングディレクタであるSteve Barlow氏によれば、どれほどの柔軟性が必要なのかを判断することも難しい。例えばCIFよりも低い解像度では、プログラマブルハードウエアでほとんどの機能に対応できる。その上のレベル(例えばセットトップボックスの機能とモバイルテレビ機能を組み合わせるようなレベル)では、ハードワイヤードのエンジンが必要になってくる。Broadcom社のアプローチは多くの点でNVIDIA社のアプローチと似ている。プログラマブルプロセッサを特殊なハードウエアで拡張する方法だ。Broadcom社の場合、16エレメントのベクタープロセッサに自社開発のCPUコアを搭載し、英Alphamosaic社(Broadcom社が買収済み)が開発した2次元レジスタファイルを組み込んでいる。このアーキテクチャは1つのチップ設計でMPEG-4をサポートできる性能を持ち、ソフトウエアを修正するだけでH.264にも適応できる。しかし、セットトップボックスレベルの性能を実現するには、固定ハードウエアブロックを増やしてアーキテクチャを拡張する必要がある。「H.264メインプロファイルのCABAC(context adaptive binary arithmetic coding)機能のように、単にベクターハードウエアとの相性が悪い場合もある。半導体技術で対応できる性能の限界に直面する時期が必ず訪れる。そうなればハードワイヤードにするほかはない」とBarlow氏は語る。
Copyright © ITmedia, Inc. All Rights Reserved.
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。