HDビデオエンコーディングのアーキテクチャ:DSPとFPGAの最適な併用法を知る(1/2 ページ)
ビデオエンコーディングのシステムでは、DSPに加え、FPGAをコプロセッサとして利用する手法がよく用いられる。HDビデオが普及し始める中、ビデオエンコーディングシステムはどのようなアーキテクチャで実現すべきなのだろうか。
HD映像とDSPの関係
映像/画像を扱う最近のアプリケーションでは、高解像度の圧縮方式を採用したものが多い。それに伴い、DSPとFPGAの両方を搭載したコプロセッシングアーキテクチャを採用する製品が増えてきた。しかし、DSPとFPGAで分割したシステムを用いることが唯一の選択肢というわけではない。今日のDSPアーキテクチャは、性能、周辺ブロック構成、ハードウエアによるビデオアクセラレーション、実装手法といった面で進化を続けている。そのため、DSPだけで対応可能なアプリケーションの範囲は著しく増加している。
DSPは、本質的にプログラム可能であり、ほとんどすべてのアルゴリズムを実行できるという柔軟性を持つ。しかし、HD(高品位)ビデオのように演算負荷が指数的に増加するアプリケーションでは、DSPの負荷を軽減するためにFPGAを採用して一部の演算処理を受け持たせることがある。
ビデオエンコーディングには、すべてのケースに対応可能な1つの方法は存在しない。使用するコーデックプロファイルが決まっている場合でも、アプリケーションによって、どの程度の演算能力とメモリー帯域幅(データの転送レート)が必要になるかは異なる。こうした要件が、ハードウエアとソフトウエアの実装方法に影響を与える重要な要素となるのである。
経験豊かな設計チームならば、ビデオエンコーディングにはおそらく標準的な圧縮アルゴリズムを選択する。コーデックを選択したら、続いてはME(motion estimation:動き推定)とMC(motion compensation:動き補償)の2つの機能に対する要件を評価するという重要な作業が必要となる。ME/ MCは、ビデオ圧縮の中で最も要求レベルの高い機能である。当然のことながら、MEエンジンとMCエンジンで必要となる演算能力とメモリー帯域幅は、映像にどれだけの動きが含まれているかに依存する。
例えばH.264/AVC(advanced video coding)コーデックは、長い時間、動きがほとんど生じないビデオ監視などのアプリケーションに適用することができる。これと対極的なのが、放送アプリケーション用のHDビデオエンコーティングである。これには、20ギガバイト/秒以上のメモリー帯域幅が必要となる可能性がある。HDビデオ会議のアプリケーションは、両者のちょうど中間に位置するものだといえ、おそらく1.5ギガバイト/秒程度のメモリー帯域幅があればよい。
ME/MCエンジンの配置
コーデックプロファイルは、設計エンジニアのために“パッケージ化された手法”が確立されたといえるまでに進歩した。しかし、コーデックプロファイルだけでなく、アプリケーションの性質も、ハードウエアアーキテクチャの実装に関してそれと同等かそれ以上の影響を与える。例えば、HDテレビ会議アプリケーションでは比較的フレーム間の動きは少ないが、放送アプリケーションでは、スポーツ競技やアクション映画など、かなりの動きを含むコンテンツを扱う必要がある。
ビデオエンコーディングにおいて、特にME/MCエンジンはハードウエアアーキテクチャの戦略にかかわる主要な要素になる。設計チームは、MEエンジンのみをFPGA上に実装するべきなのか、それともMEエンジン/MCエンジンの両方のアクセラレーションが必要なほどに演算負荷が大きいのかといったことを考慮しなければならない。必要なメモリー帯域幅は20ギガバイト/秒以上にもなり得るが、これも演算負荷と同様に重要である。FPGAの設計では、DSPだけでサポート可能なレベル以上にメモリー帯域幅を拡張できるようにするかもしれない。あるいは、必要に応じてメモリー帯域幅を拡張可能にすることも考えられる。
H.264/AVC High Profileは、放送アプリケーションで用いられるHDエンコーディング用アーキテクチャである(図1)。MEの値の算出に当たっては、現在のフレームと、それが参照する各フレームがマクロブロックに再分割される。マクロブロックのサイズは通常16ピクセル×16ピクセルだが、最小で4ピクセル×4ピクセルの場合もある。マッチングのプロセスでは、現在のフレームから、あらかじめ定義された最小エラー基準を満たす参照フレーム内にマクロブロックを配置するよう検索が行われる。MEでは一般的にSAD(sum of absolute differences)というエラー基準が用いられる(以下参照)。
ここでxは参照フレームのマクロブロック、yは現在のフレームのマクロブロック、[i][j]はフレームの行(i)と列(j)を表す。アプリケーションによって、MEエンジンが1サイクル当たり64回だけ計算すればよい場合もあれば、何千回も計算しなければならないこともある。この差は大きく、ハイエンドのアプリケーションでは、このことが複数のDSPを持つアーキテクチャとするのか、別個にFPGAベースのアクセラレータを用意して計算の一部を分担させるのかを決める要因になることもある。

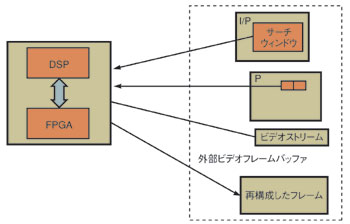 図2 DSPとFPGAによるパイプライン処理 マクロブロックベースのパイプライン処理では、過去の参照フレームを基準にしてPフレーム(中央)をエンコードする。その際の参照フレームは、直近のものであればPフレームでもIフレーム(上)でもよい。
図2 DSPとFPGAによるパイプライン処理 マクロブロックベースのパイプライン処理では、過去の参照フレームを基準にしてPフレーム(中央)をエンコードする。その際の参照フレームは、直近のものであればPフレームでもIフレーム(上)でもよい。FPGAを必要とする理由が、SADの計算の高速化のためなのか、それともメモリー帯域幅のためなのかにかかわらず、FPGAを効果的に使うには、DSPとFPGAとが密接に結合して通信する必要がある。マクロブロックベースのパイプライン処理手法は、この設計上の課題に対応したものである(図2)。またこの手法では、複数のマクロブロックを処理するために十分な内部バッファを用意する。あるマクロブロックの処理を行っている際、内部バッファに書き込みを行う間に、ほかのバッファ内にある処理済みのマクロブロックのデータを次の演算ユニットに移動することができる。
同期設計では、DSPとFPGAが特定の順序と粒度でメモリーにアクセスすることが重要である。また、遅延やバスの競合、アライメントの問題、DMA(direct memory access)の転送速度、搭載メモリーの種類などに依存するクロックサイクル数を最小化することが重要だ。
同様に、チップ間の通信も、実装モデルにおいて重要な要素である。図3(a)のアーキテクチャでは、FPGAに実装しているのはMEエンジンのみだ。一方、図3(b)のアーキテクチャではMEエンジンとMCエンジンの両方をFPGAに実装している。後者のアーキテクチャでさらに困難な点は、MEエンジンとMCエンジンが連続的に相互に通信する必要があるという点だ。このアーキテクチャではMEエンジンだけでなく、メモリーバッファ、デブロッキングフィルタ、CABAC(context adaptive binary arithmetic coding)またはCAVLC(context adaptive variable length coding)ブロックもDSPからFPGAに移している。なお、CABACは、ビデオストリームにおけるシンタックス要素を圧縮するものである。CAVLCはCABACほど複雑ではなく、量子化された変換係数の値を符号化する。
図3(b)のアーキテクチャでは、DSPとFPGAの機能のバランスを維持し、H.264/AVCエンコーディングの高い性能と柔軟性を実現できる。しかし、DSPとFPGAとの間でのメモリーデータ転送と通信プロトコルの実装は複雑になる可能性がある。そのため、可能ならばこのアーキテクチャは採用しないほうがよい。一方、図3(a)のアーキテクチャでは、DSPとFPGA間のメモリーデータ転送と通信プロトコルが簡素化されている。従って、多くの場合、こちらを選択したほうがよい。
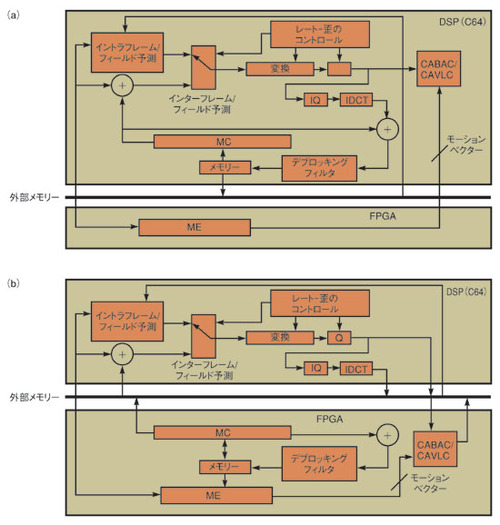 図3 DSPとFPGAを用いたアーキテクチャ DSPでMCを実行し、FPGAでMEを実行するために特に必要となるのは、通信プロトコルだけである(a)。一方、FPGAでMC/MEを実行する手法では、DSP、FPGA、システムメモリーの3者間での相互作用が増加する。
図3 DSPとFPGAを用いたアーキテクチャ DSPでMCを実行し、FPGAでMEを実行するために特に必要となるのは、通信プロトコルだけである(a)。一方、FPGAでMC/MEを実行する手法では、DSP、FPGA、システムメモリーの3者間での相互作用が増加する。Copyright © ITmedia, Inc. All Rights Reserved.
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。