メモリーシステムの設計ポイント:プロセッサの性能はこれで決まる!(1/4 ページ)
今日のプロセッサでは、複雑なメモリーシステムを組み込むことにより、プロセッサ性能や消費電力、コスト効率などを向上させている。本稿では、組み込みの密結合メモリー(TCM)やキャッシュなどについて解説することで、メモリーシステム設計のポイントを明らかにする。
プロセッサ性能の低下を避ける
プロセッサの最も重要な性能は、一定時間内にどれだけの処理を実行できるかということである。EEMBC(embedded microprocessor benchmark consortium)ベンチマークは、Dhrystone MIPS(millions of instructions per second)ベンチマークのスコアとは異なり、組み込みシステムアプリケーションのタスクを実行するプロセッサの性能を表す。しかし、EEMBCベンチマークのバージョン1.0では、実際の処理性能におけるメモリーシステムなどの影響は測定されない。これは、同バージョンのテストがほとんどの場合、メモリーとしては、プロセッサのL1キャッシュメモリー(以下、キャッシュ)だけを用いて実行可能であるためだ。この点を考慮し、EEMBCの次バージョンでは、ネットワークやデジタルエンターテインメント向けのシステムレベルのベンチマークにより、大容量のキャッシュを持つプロセッサに対しても、より現実的な負荷をかけることができるようになる予定だ。
近年、プロセッサの処理能力が向上したことにより、全体の処理時間に対するメモリーアクセス遅延の割合が大きくなってきた。そのため、システム内のメモリーの種類や容量、アクセス方式などは、プロセッサコアの性能の上限を決定する要素としての重要性を増してきた。言い換えれば、最適なメモリーシステムを決定することが、以前にも増して重要になったのだ。
英ARM社でプロセッサ部門のフェローを務めるGerard Williams III氏によると、「プロセッサの理想的なメモリーシステムとは、決してキャッシュミスがなく、遅延のないアクセスを提供するものだ」という。
チップ設計者は、プロセッサのIPC(instructions per cycle:サイクル当たりの処理命令数)を理解してから、性能の低下を最小限に抑えるようなメモリーシステムを実装する必要がある。この性能低下は、初期参照ミスや容量性ミス(キャッシュしたいデータ量がキャッシュ容量を超えることで発生するミス)、競合性ミスなどによるキャッシュミスやメモリーアクセスの効率に起因する。
最適なメモリーアーキテクチャを採用してメモリーシステムを構成すれば、プロセッサの最大IPCをそのまま維持することができる。一方、メモリーシステムが不適切だと、コアの実行ユニットに無駄なアイドルが生じて、プロセッサの性能を著しく低下させてしまうことになる。しかし、プロセス技術が微細化するに連れ、プロセッサコアとメモリーの間の性能ギャップは大きくなる。そのため、プロセッサコアの性能に悪影響を及ぼさないようなメモリーシステムを構築/実装することは、ますます困難になってきている。プロセッサコアのクロック周波数の向上が著しいため、メモリーアクセス遅延を短縮しても、その効果が相対的には小さいものとなってしまうのだ。
同様に、ソフトウエア開発者がメモリーシステム内に巧妙にプログラムの命令やデータを配置することによっても、プロセッサの最大IPCを維持することができる。逆に、メモリーシステム内の命令やデータの配置がアプリケーションの使用傾向に適合していなければ、プロセッサの性能は大きく低下してしまうだろう。米Freescale Semiconductor社は、M1メモリー(1次キャッシュまたはL1キャッシュ)における競合を回避するためのアプリケーションノートを作成している。それには、最悪の場合で54%にもなるメモリーコンテンション(メモリーアクセス権の争奪)によるプロセッサ性能の低下を、開発者がデータバッファを適切に配置することにより回避できるという例が示されている*1)。
一般的に、メモリー内の命令やデータの配置の最適化に対し、コンパイラやプロファイリングツールで支援できる範囲は限られている。提供される最適化機能としては、例えば米Green Hills Software社の「Optimizing Compilers」には、キャッシュヒット率を最適化するためにメモリー上のプログラムファンクションを並べ替える機能がある。また、米Texas Instruments社のコンパイルツール「CodeSizeTune」は、プログラムをコンパイルする際、コードサイズや実行速度などに関して自動的にプロファイリングし、開発者が最適なコンパイル設定を行えるよう支援する(図1)。しかし、一般的には、高効率なシステムやリアルタイム処理が求められるシステムの多くでは、処理リソース/メモリーリソースの非効率的な使用に起因する不要なコストの発生を避けるために、ソフトウエア開発者にはメモリーシステムに対する理解が求められる。
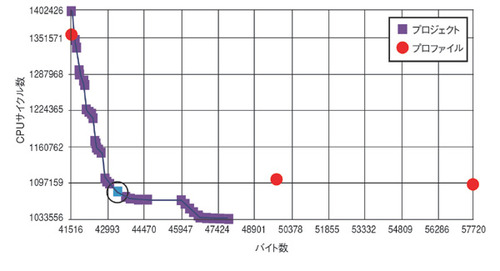 図1 CodeSizeTuneを適用した結果の例 CodeSizeTuneを利用することにより、ソフトウエア開発者は、構成やコンパイラ設定による効率の違いを視覚的に調査/比較し、コードサイズと処理サイクルの間の最適なバランスを決定することができる(提供:TexasInstruments社)。
図1 CodeSizeTuneを適用した結果の例 CodeSizeTuneを利用することにより、ソフトウエア開発者は、構成やコンパイラ設定による効率の違いを視覚的に調査/比較し、コードサイズと処理サイクルの間の最適なバランスを決定することができる(提供:TexasInstruments社)。脚注
※1…Schuchmann, David, "Tuning an Application to Prevent M1 Memory Contention," Application Note AN3076, Freescale Semiconductor Inc, May 2006.
Copyright © ITmedia, Inc. All Rights Reserved.
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。